Inside this section, we’ll assume that:
•You want to save all the changes made to a table named “TableT” located inside your database
•There is a column named “LAST_UPDATE_TIME” inside the “TableT” (that contains the last time the row has been updated).
•No row is ever deleted from the source database (i.e. there are only INSERT and UPDATE operations).
•There is a column named “ID” inside the “TableT” (that contains the primary key)
•All the historical data from the “TableT” will be saved inside the file “HistoricalData.gel_anatella”
•The file “HistoricalData.gel_anatella” contains 3 more additional columns (in addition to the columns from the Table “TableT”) that are named “RECORD_VALIDITY_FROM”, “RECORD_VALIDITY_TO” and “RECORD_CURRENT_FLAG”.
Here is the initial data extraction graph. You only run this graph one time to create the initial version of “HistoricalData.gel_anatella”:
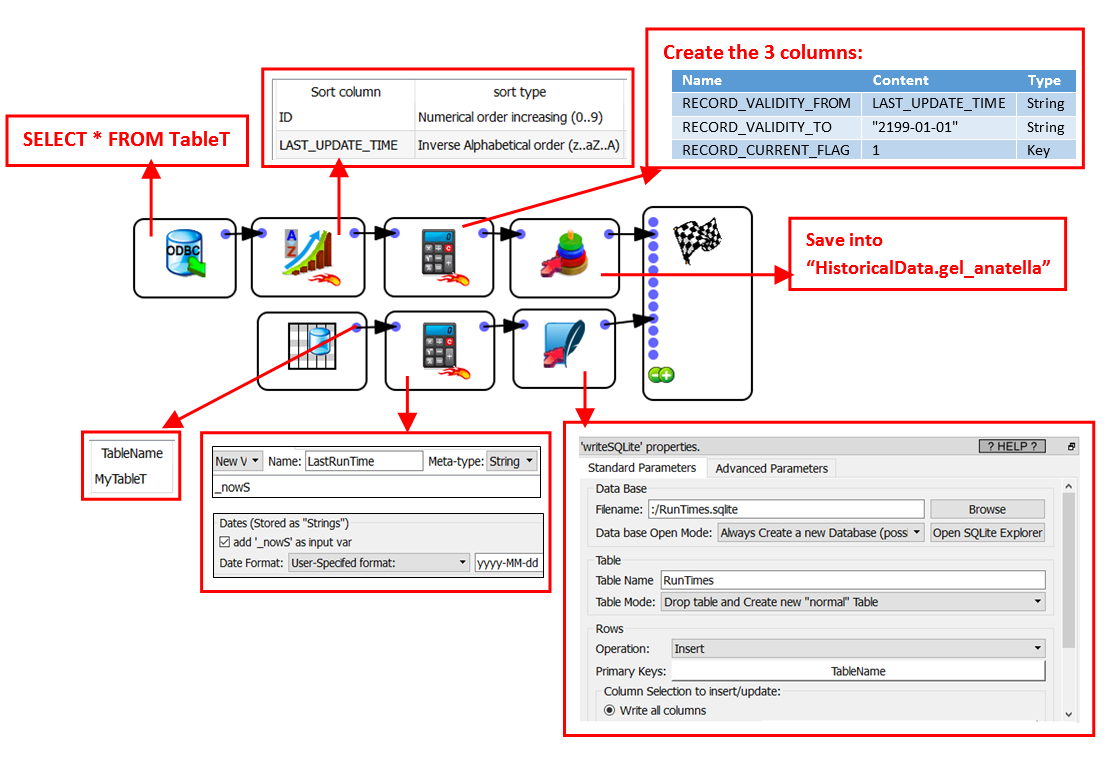
Please note that we used herabove a small SQLite file to keep track of the last time that we are running the extraction procedure.
You’ll find on the next page the “incremental” extraction procedure that we run everyday. This is a quite straightforward Anatella graph.
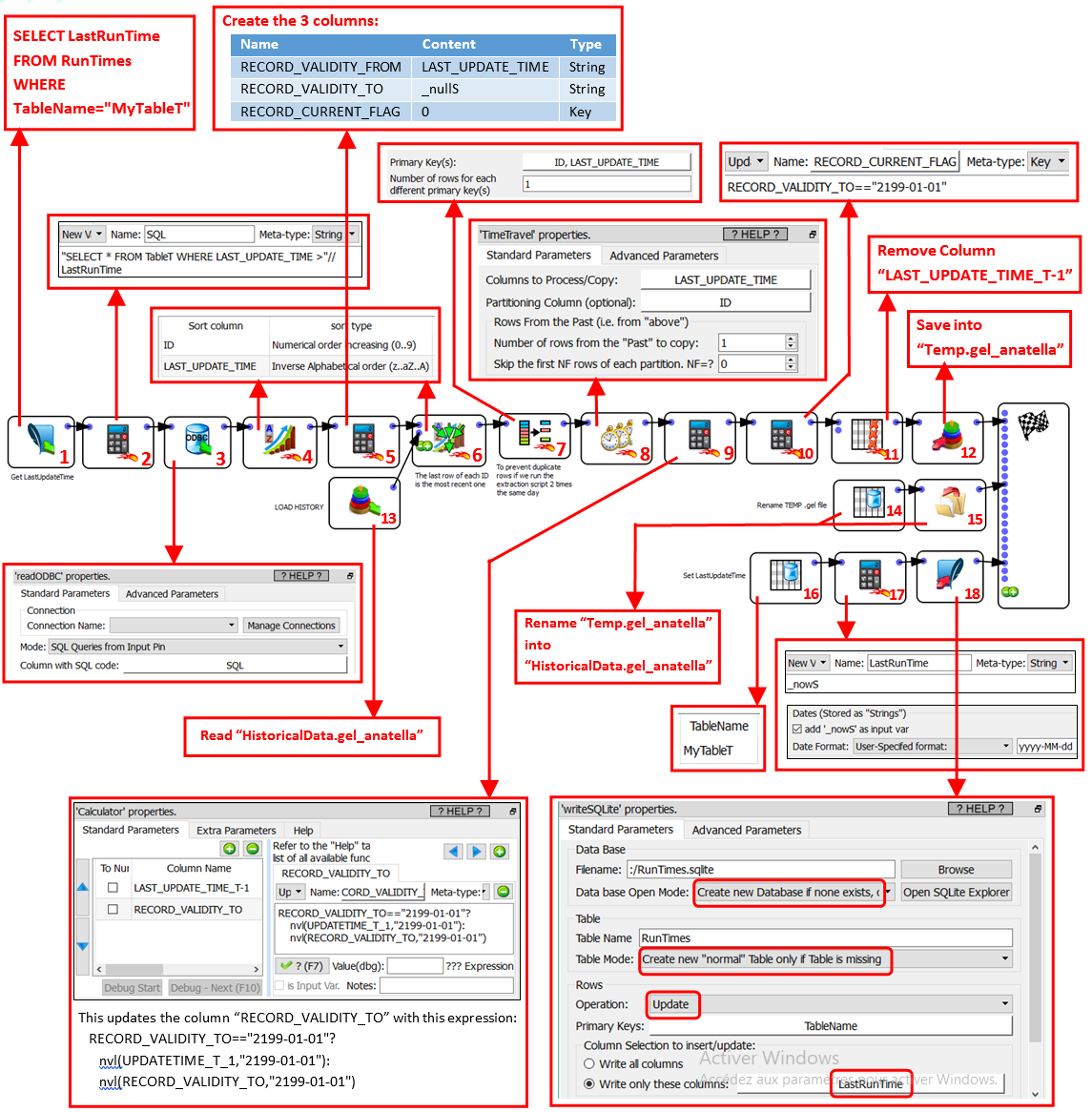
Inside the above graph, we gave a small ID number to each Action. Here is a small summary of the objective of each Actions:
•Actions 1,2: This computes the SQL query to run inside your database taking into account the date of the last execution of the extraction procedure.
•Action 3: This actually extract from the database all the new rows.
•Actions 4,5,6,13: This merges the new rows (that we just extracted) with the “old” rows (that were extracted a long time ago and that are stored inside “HistoricalData.gel_anatella”). In particular, the new rows (coming from the data base) are missing the 3 columns named “RECORD_VALIDITY_FROM”, “RECORD_VALIDITY_TO” and “RECORD_CURRENT_FLAG”, so, (using the Action 5) we add them.
•Action 7: Just a small “RowDeduplicate” Action to prevent duplicate rows if we run the extraction script 2 times on the same day
•Action 8,9: On some rows, we must update the column “RECORD_VALIDITY_TO”. The update expression only working because the table is sorted in a very specific way (see the Action 6 to know the exact Sort Order).
•Action 10: Update the column “RECORD_CURRENT_FLAG”.
•Actions 11,12,14,15: self-explaining.
•Actions 16,17,18: We save inside the SQLite file the date from today as the “last extraction date” (i.e. the last date when we ran the extraction procedure).
The above “incremental” extraction procedure is very efficient because, each day, it only sorts the “new” rows (i.e. it does not sort the whole historical data). Still, it’s able to properly update the column “RECORD_VALIDITY_TO” over the whole historical table.