All databases are using an INDEX structure that allows them to quickly find a particular cell in a large table containing billions of cells: I suggest you to read the section 10.10.1. about this subject if you didn’t do it yet.
One very annoying side-effect of using an INDEX structure is that the “insert” type of operations are very slow. Indeed, each time you insert a new row inside a table, you must update the INDEX structure to reflect the presence of this new row: This is *very* slow! There are several “tricks” that you can use to avoid losing time (because always updating this INDEX structure after each insertion of a new row consume a large amount of time): i.e. To add many rows inside an already existing Table T at high speed, you can use different solutions:
•“Fast INSERT” Solution 1
The solution 1 is composed of 3 steps:
oDelete all INDEX structures built on top of table T (i.e. run many “DROP INDEX” SQL commands)
oInsert your new rows
oRe-create all the INDEX structures built on top of table T (i.e. run many “CREATE INDEX” SQL commands)
Most of the time, this first solution is impractical and it’s almost never used.
Indeed, when using the solution 1, there are no “INDEX” on your table anymore during a brief amount of time (i.e. during the time required to insert all your rows): ..And this is very dangerous because all the processes that are attempting to run a query on the Table T will most certainly fail (because these processes will “time out” because they will run very slowly because there are no “INDEX” currently available). Furthermore, the time required to re-create all the INDEXes is usually so large that it completely nullifies the speed gain obtained by inserting the row at a slightly higher speed.
•“Fast INSERT” Solution 2
The solution 2 is also composed of 3 steps:
oInsert all your new rows inside an intermediary table that has no INDEX
oRun a “INSERT INTO <Table T> SELECT * FROM <Intermediary Table>” SQL command.
If the database engine is correctly coded, it should see that it only need to update one time the INDEX structure, once all the rows from the intermediary table have be added to the final Table T.
oEmpty the intermediary table (i.e. run a “TRUNCATE TABLE” SQL command)
When you directly insert news rows one-by-one inside the final Table T (in a simple, straightforward way), the database engine must update the INDEX structure thousands of times (i.e. there is one update for each inserted row). Using the “solution 2” allows to reduce the number of updates of the INDEX-structure to only one, leading to a large gain in time.
Unfortunately, the solutions 2 also involves copying a large amount of data (from the intermediary table to the final Table T). This large “copy” operation might consume so much time that, at the end, the final gain in time might be null.
•“Fast INSERT” Solution 3
When Anatella communicates with a database, it sends to the database a large buffer that contains many INSERT expressions to be executed by the database engine. The quantity of INSERT operations that are sent inside the same buffer to the database engine is defined using the parameter named “BULK Operation” here:
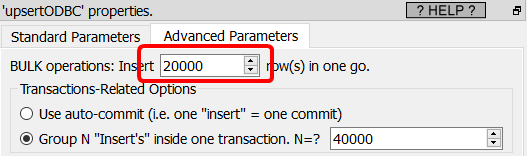
Most (Java) ETL engines are not able to use any BULK Operations: i.e. They are sening to the database engine only one only “INSERT” SQL command at-a-time. Doing so, leads again to a very low insertion speed (because, for each inserted row, there is an update of the INDEX-structure). More precisely, if there are N rows to “insert”, the ETL engine will send N “text buffer” to the database engine, (each “text buffer” containing one “INSERT” SQL command) and the database engine might then run N “INDEX-structure-update”.
A clever database engine will see that this “buffer” contains many INSERT statements (several thousands) and only update the INDEX-structure once the complete set of INSERT statements has been completely processed. Thus, instead of running an “INDEX-structure-update” for each inserted row, we run an “INDEX-structure-update” every 10 thousand rows (i.e. at the end of each buffer). This leads to large time savings (but, unfortunately, not all databases are “clever”).
•“Fast INSERT” Solution 4
Anatella is also able to include inside the same transaction many different “INSERT” statements. For example, if you want to “group together” 3 “INSERT” statements together inside the same transaction, you can use the following parameters insde Anatella:
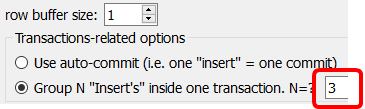
A clever database engine will see that each transaction contains many INSERT statements (sometime several thousands) and only update the INDEX-structure once the complete set of INSERT statements has been completely processed (i.e. when the transaction ends with the “COMMIT” statement). Thus, instead of running an “INDEX-structure-update” for each inserted row, we run an “INDEX-structure-update” every 10 thousand rows (i.e. at the end of each transaction). This usually leads to large time savings.
Unfortunately, running any kind of transactions inside a database always incurs a large overhead (because of the mechanims used to guarantee the ACID properties of the transactions, that are very time-consuming). This processing overhead dramatically slows down the “INSERT” speed. So, the time gained by reducing the number of “INDEX-structure-update” might anyway finally be lost again because of the overhead of the transaction mechanism.
![]()
Which “Fast INSERT” solution (1-4) is best for which database?
Oracle: Solution 4 (or 3) is usually the best
MS-SQLServer: Solution 3 (or 4) is usually the best
Teradata: Solution 2 is usually the best (if you use it at the same time as the special TeradataWriter Action)
DB2: Solution 4 is usually the best (the DB2 database does not exactly support transactions but the “commit” keyword is usefull to improve the “INSERT” speed for still other reasons)